Please wait...
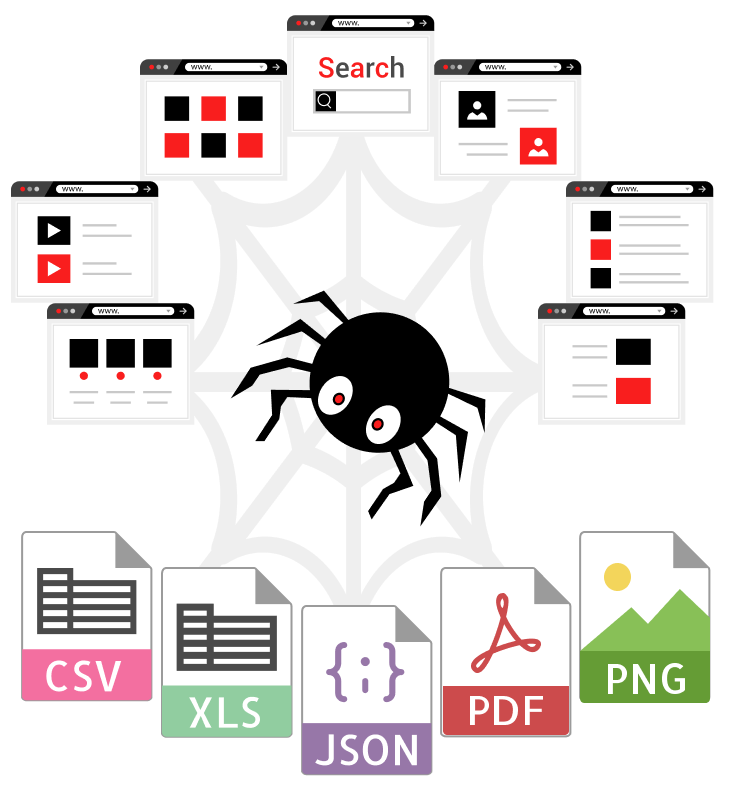
Visual web scraper extracts data from any website.
We help people to Automate web scraping tasks, extract, process, and transform data from multiple pages at any scale.
Click to extract text, images, attributes with a point-and-click web scraper interface.
We visit web pages on your behalf, render Javascript-driven pages with headless Chrome in the cloud, return static HTML, and capture screenshots or save as PDF.





 Google Maps Scraper.
Google Maps Scraper.
 AliExpress scraper.
AliExpress scraper.
 Twitter scraper.
Twitter scraper.