Please wait...
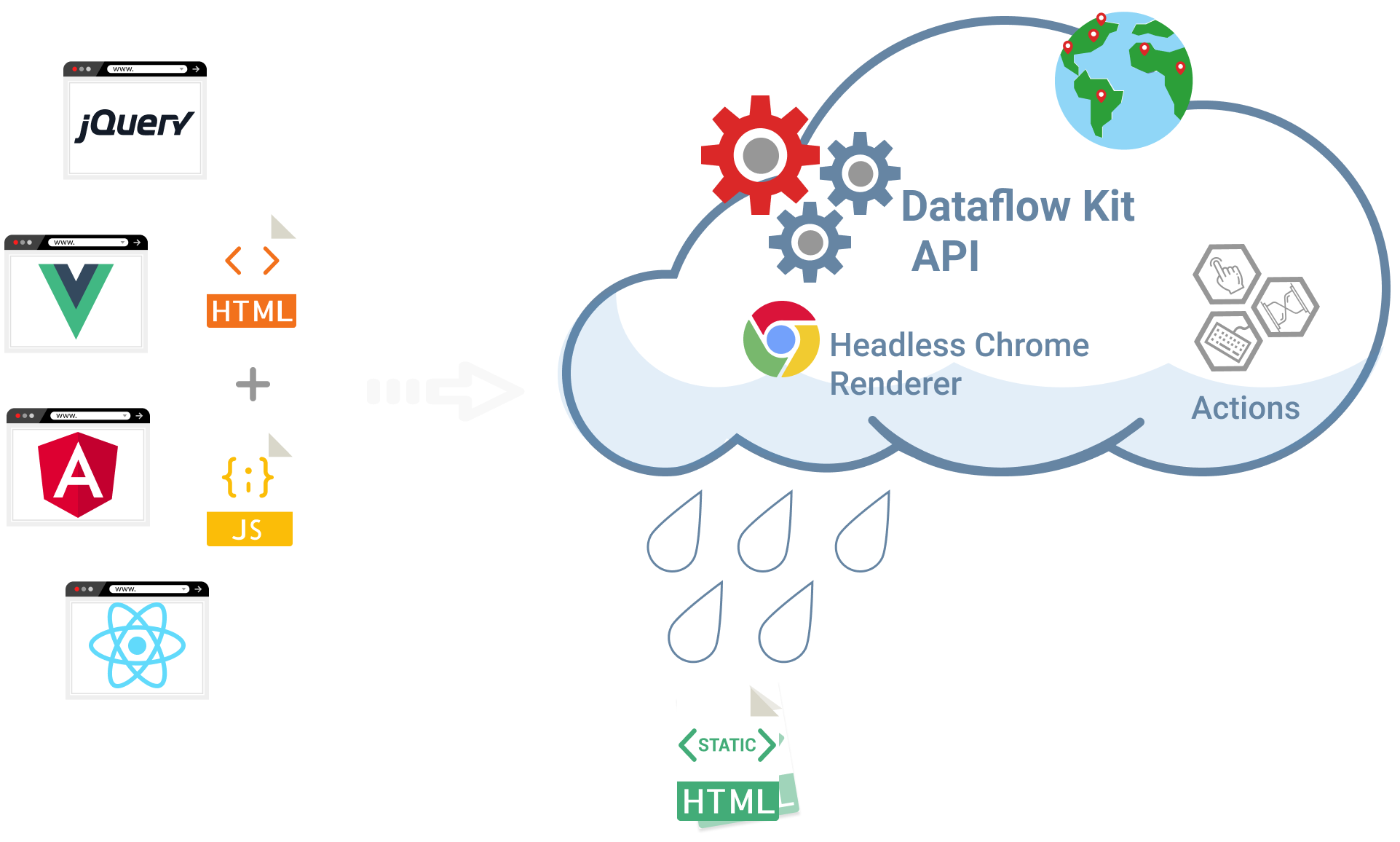
HTML Scraping from any website.
Execute Javascript code and render dynamic content to static HTML with Headless Chrome in the cloud.
We route HTTP requests via a worldwide proxy network according to specified target geolocation.