Please wait...
Getting Started
With Dataflow Kit web scraper, extracting data is as easy as clicking the data you need.
This guide is useful as a general reference for common tasks associated with data collection building.
A collection is a set of instructions outlining the actions to be performed against a specific website. These instructions are consumed by Dataflow Kit servers to gather data from a target website thereafter.
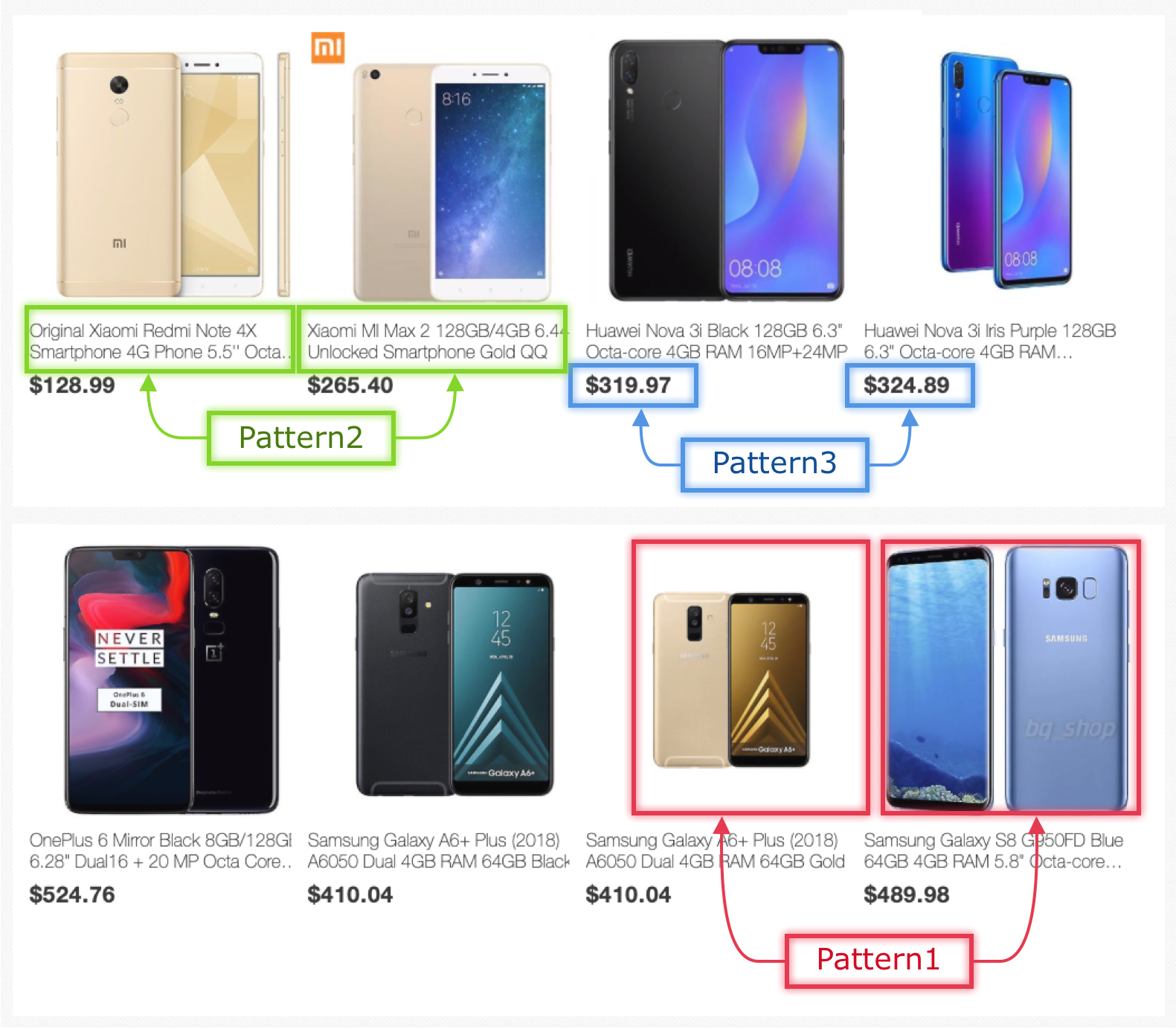
The scraping process is based on the pattern of data you have selected. Look at the sample screenshot taken from a webshop results. Let's say we want to scrape the Image, title of item listed and the price.